Day 2 Optimizer 옵티마이저 +코드 팁
by daramiTip & 내 생각
- 텐서 플로우 튜토리얼도 너무 좋다.
- tf.kr (페이스북 그룹) 여기 좋음
- tensor flow, pytorch 둘다 공식 문서 너무 좋다.
💖🚀🌟 아이패드로 렉처 보면서 생각하기 -> 유용하더라. 렉처 읽으면서 생각하기
1. 모멘텀 옵티마이저
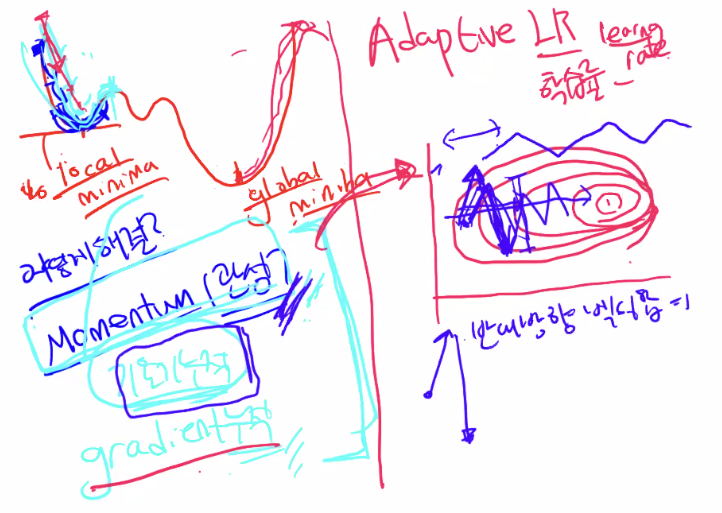
기울기를 누적해서 벗어나는 힘을 주자 (관성의 힘을 이용해서)
배치 사이즈가 요동이 칠 수 밖에 없다. 반대 방향 벡터의 합은 변동 폭을 줄어들게 한다.
앞으로 가는 힘은 동일하다. (반대 방향 힘 상쇄, 최적점으로 가는 힘 누적)
2. Adaptive LR
학습률 맨날 고정했었는데, 변화하면 어떨까?


-> 가중치별로 다르게 학습률을 가진다.
RMS Prop -> Ada grad의 단점 보완한다.
-> 너무 과거의 거를 가져오게 된다는게 어떤의미인가용?

------ 다 더하는게 아니라 평균을 내서 단점을 보완한다.
3. Adam : 짬뽕 ( Momentun + Adapted LR)
: 가장 많이 쓰임 (기울기 누적+ 적응 학습률)

꼭 모멘텀 오늘 한번에 정리해놓기
모멘텀(Momentum)은 관성이라는 물리학의 법칙을 응용한 방법입니다. 모멘텀 SGD는 경사 하강법에 관성을 더 해줍니다. 모멘텀은 SGD에서 계산된 접선의 기울기에 한 시점(step) 전의 접선의 기울기값을 일정한 비율만큼 반영합니다.
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=lego7407&logNo=221681014509
Deep Learning - 6장. 학습관련 기술(SGD, Momentum, Adagrad, Adam)
손실 함수의 값을 줄여나가면서 학습하는 방법은 어떤 옵티마이저를 사용하느냐에 따라 달라집니다. 여기서...
blog.naver.com
어떤게 더 괜찮아 보이나요. 답은 없다. 하지만,

1. 제일 중요한건 일관성
-> 일관성이 없는 코드들을 보면
협업 힘들다, 복붙, 난잡 이런 생각 든다.

2. 재사용 가능 하게 함수 코드 짜기
옵티마이저 sgd 사용했을때 아무 문제 없었나요? Nan이 나오는 경우도 많다.
-> 모델이 터지는 경우도 간혹 있다. 스케쥴러 같이 사용하기도 한다.
안전하게 사용하는 법: 'SGD파': 학습률을 엄청 작게하기 -> 학습 오래 걸린다.
대기업의 컴퓨팅 파워..?
'🚀💖🎶 > AI, 개발 흔적' 카테고리의 다른 글
| [나만의 언어] 자연어 처리 /불용어/어간추출/임베딩 등 (1)(2) (0) | 2021.12.26 |
|---|---|
| Day 3 더나은 신경망 학습을 위한 방법들 (0) | 2021.12.21 |
| Day1 섹션 4 딥러닝 (0) | 2021.12.17 |
| 프로젝트 전 리뷰 (0) | 2021.12.07 |
| flask+코드+반성ing (0) | 2021.12.02 |
블로그의 정보
다람
darami